Trong thời đại dữ liệu thống trị mọi hoạt động kinh doanh, Data Pipeline đã trở thành bộ khung cốt lõi giúp doanh nghiệp thu thập, xử lý và vận hành dữ liệu một cách tự động, nhanh chóng và tin cậy. Một hệ thống pipeline tốt sẽ biến dữ liệu thô từ nhiều nguồn khác nhau thành “nguồn dữ liệu sạch” sẵn sàng phục vụ phân tích, báo cáo và ra quyết định chiến lược.
Cách hoạt động của Data Pipeline
Tưởng tượng dữ liệu như nguyên liệu thô trong một dây chuyền sản xuất. Data Pipeline chính là hệ thống cho phép chuyển đổi dữ liệu đó từ dạng nguyên thủy sang một dạng “sản phẩm hoàn chỉnh”, sẵn sàng sử dụng trong các phân tích hoặc mô hình AI.
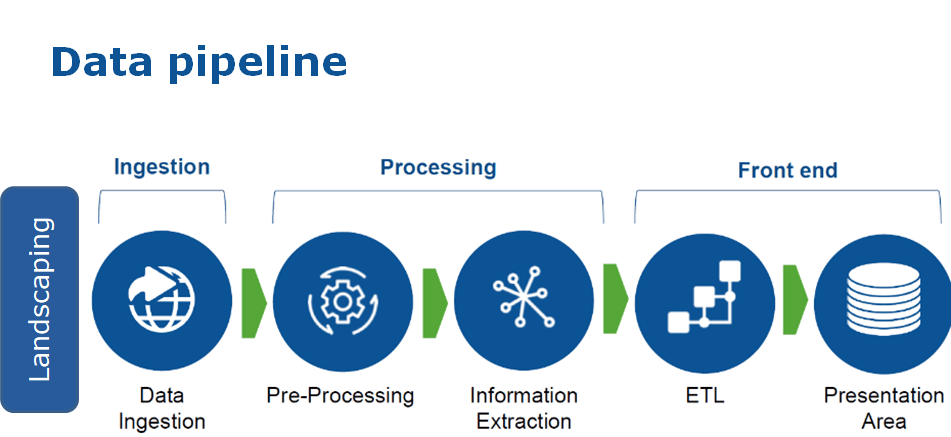
1. Thu thập dữ liệu (Data Ingestion)
Đây là bước đầu tiên và cũng là bước nền tảng của pipeline: dữ liệu được thu thập từ nhiều nguồn khác nhau. Trong doanh nghiệp hiện đại, các nguồn này có thể bao gồm:
- Hệ thống nội bộ (CRM, ERP, POS,…)
- Dữ liệu bên ngoài như Google Analytics, dữ liệu thị trường hoặc mạng xã hội.
- Dữ liệu từ thiết bị IoT, máy móc sản xuất, log system.
Việc thu thập không chỉ là “gom dữ liệu”, mà phải đảm bảo đầy đủ, đúng loại và kịp thời để không tạo ra sai lệch ở các bước tiếp theo.
2. Chuyển đổi dữ liệu (Data Transformation)
Dữ liệu từ nguồn thường tồn tại dưới nhiều định dạng, có thể chứa lỗi, thiếu thống nhất hoặc bị trùng lặp. Vì vậy, dữ liệu cần được xử lý trước khi sử dụng, bao gồm:
- Làm sạch – loại bỏ dữ liệu lỗi hoặc trùng lặp.
- Chuẩn hóa – thống nhất định dạng ngày tháng, đơn vị đo lường…
- Gộp – liên kết dữ liệu từ nhiều hệ thống khác nhau.
- Tạo thêm trường mới để phục vụ cho phân tích.
3. Lưu trữ và phân phối dữ liệu (Data Storage)
Sau khi đã được xử lý, dữ liệu cần được đưa vào một nơi lưu trữ tập trung để phục vụ các nhu cầu phân tích, báo cáo hoặc mô hình hóa. Đây có thể là Data Warehouse, Data Lake hoặc Data Lakehouse tùy thuộc vào mục tiêu sử dụng và quy mô dữ liệu.
Dữ liệu sau khi được pipeline xử lý sẽ là “thành phẩm” – sạch, đồng nhất và sẵn sàng cho các công việc như dashboard BI, phân tích chiến lược, hay huấn luyện mô hình Machine Learning.
Các loại Data Pipeline thường gặp
Không phải mọi dữ liệu đều được xử lý theo cùng một cách. Tuỳ vào yêu cầu vận hành và mục tiêu kinh doanh, doanh nghiệp có thể lựa chọn mô hình pipeline phù hợp nhất.
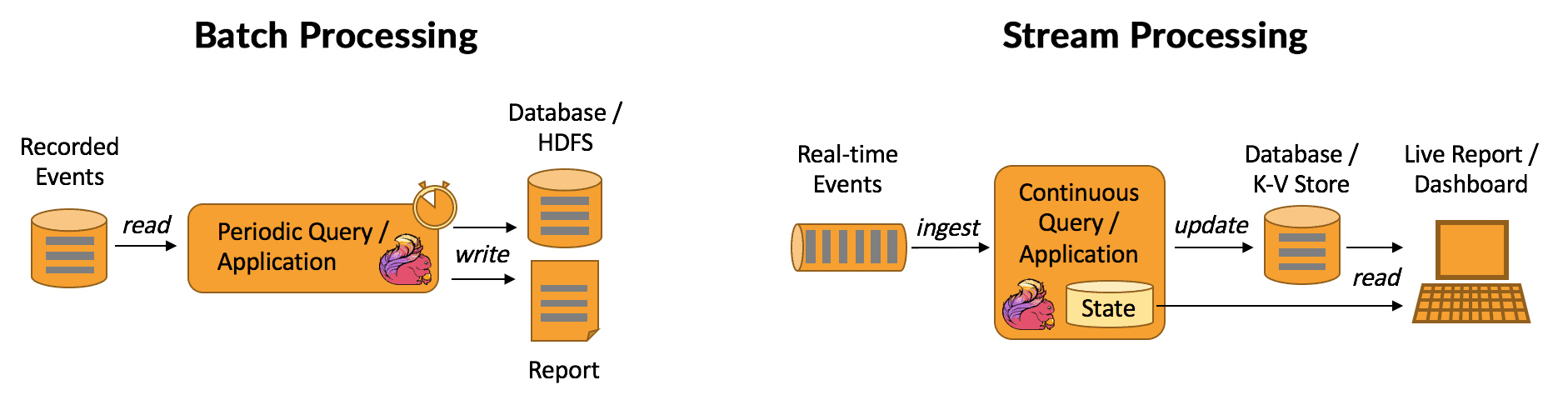
1.Batch Processing (Xử lý theo lô)
Đây là hình thức thu thập dữ liệu trong khoảng thời gian nhất định và dữ liệu không cần xử lý ngay lập tức (có thể theo hàng giờ, hàng ngày, hàng tháng).
Đối với Batch Processing, hình thức thu thập dữ liệu này sẽ xử lý được lượng dữ liệu lớn cùng lúc với quy trình ổn định và dễ dàng kiểm soát. Tuy nhiên, Batch Processing sẽ không phù hợp với doanh nghiệp cần phân tích dữ liệu thời gian thực.
- Ví dụ minh hoạ: Trong một công ty FMCG như Vinamilk, lượng dữ liệu bán hàng từ hàng ngàn điểm phân phối có thể được thu thập hàng ngày và xử lý theo một “lô” để tạo báo cáo doanh số tổng hợp cuối ngày cho ban tài chính.
2. Streaming Data (Xử lý theo luồng)
Streaming Data là hình thức xử lý dữ liệu ngay khi nó được tạo ra gần như real-time. Vậy nên doanh nghiệp dễ dàng phân tích và kịp thời ra quyết định nhanh với tình huống mới. Đồng thời, hình thức này phù hợp trong các ứng dụng giám sát trực tiếp tuy chi phí kiến trúc cao hơn và phức tạp hơn khi triển khai.
- Ví dụ minh hoạ: Trong kho lạnh bảo quản sản phẩm, cảm biến IoT gửi dữ liệu về nhiệt độ và độ ẩm liên tục. Streaming pipeline xử lý ngay dữ liệu này và có thể gửi cảnh báo tức thì nếu thông số vượt mức an toàn, giúp doanh nghiệp giảm thiểu rủi ro hư hỏng hàng.
Data Pipeline là nền tảng không thể thiếu của mọi hệ thống dữ liệu hiện đại. Việc hiểu rõ cách hoạt động và lựa chọn đúng loại Data Pipeline không chỉ giúp doanh nghiệp tận dụng dữ liệu hiệu quả mà còn tạo ra lợi thế cạnh tranh trong môi trường số hóa ngày càng sâu rộng.


