In an era where data underpins virtually every business activity, Data Pipelines have become the foundational framework that enables enterprises to collect, process, and operationalize data in an automated, fast, and reliable manner. A well-designed pipeline transforms raw data from multiple sources into a “clean data foundation” ready to support analytics, reporting, and strategic decision-making.
How a Data Pipeline works
Imagine data as raw materials in a production line. A Data Pipeline functions as the system that converts this raw input into a “finished product” – data that is structured, refined, and ready for use in analytics or AI models.
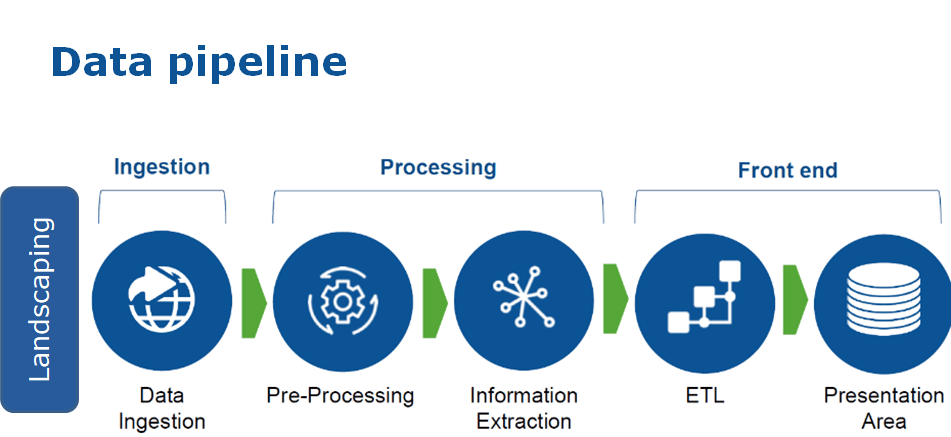
1. Data ingestion
This is the first and most fundamental stage of the pipeline, where data is collected from a variety of sources. In modern enterprises, these sources may include:
- Internal systems (CRM, ERP, POS, etc.)
- External data such as Google Analytics, market data, or social media platforms
- Data from IoT devices, manufacturing equipment, and system logs
Data ingestion is not merely about “gathering data,” but about ensuring completeness, accuracy, relevance, and timeliness to prevent downstream inconsistencies and analytical errors.
2. Data transformation
Source data typically exists in multiple formats and may contain errors, inconsistencies, or duplicates. Therefore, data must be processed before use, including:
- Cleansing – removing erroneous or duplicate records
- Standardization – unifying formats such as dates, currencies, and units of measurement
- Integration – combining data from multiple systems
- Enrichment – creating additional fields to support analytical use cases
3. Data storage and distribution
Once processed, data is loaded into a centralized storage environment to support analytics, reporting, or modeling. Depending on business objectives and data scale, this may include a Data Warehouse, Data Lake, or Data Lakehouse.
Data that has passed through the pipeline becomes the “finished output” – clean, consistent, and ready for BI dashboards, strategic analysis, or Machine Learning model training.
Common types of Data Pipelines
Not all data requires the same processing approach. Depending on operational needs and business objectives, enterprises can select the most appropriate pipeline model.
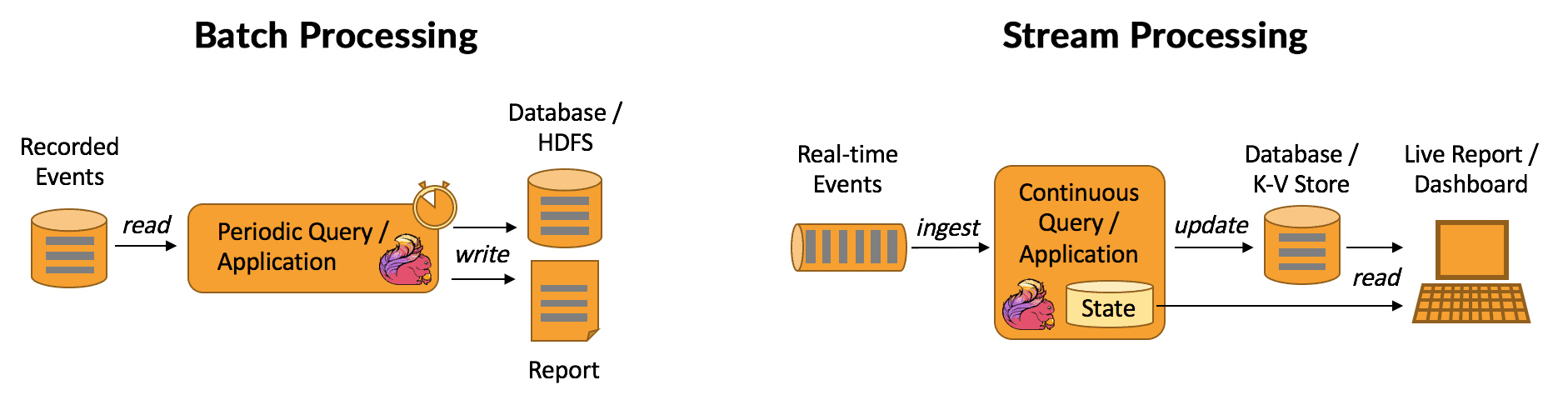
1. Batch Processing
Batch processing involves collecting data over a defined time interval, where immediate processing is not required (e.g., hourly, daily, or monthly).
This approach enables the processing of large data volumes at once, with stable and easily controlled workflows. However, batch processing is not suitable for enterprises that require real-time data analysis.
- Illustrative example: In an FMCG company such as Vinamilk, sales data from thousands of distribution points can be collected daily and processed in batches to generate end-of-day consolidated sales reports for the finance team.
2. Streaming Data Processing
Streaming data processing handles data almost immediately as it is generated, enabling near real-time analysis and rapid decision-making. This approach is particularly well-suited for real-time monitoring applications, although it involves higher architectural complexity and cost.
- Illustrative example: In a cold storage facility, IoT sensors continuously transmit temperature and humidity data. A streaming pipeline processes this data instantly and can trigger real-time alerts if thresholds are exceeded, helping enterprises minimize the risk of product spoilage.
Data Pipelines are an indispensable foundation of modern data systems. Understanding how they operate and selecting the right type of Data Pipeline not only enables enterprises to fully leverage their data assets but also creates a sustainable competitive advantage in an increasingly data-driven digital landscape.


